Tinybird's Core: ClickHouse
Tinybird is built around ClickHouse, a database designed for blazing-fast analytical queries on massive datasets. But why is it so fast? Let’s explore the core concepts that make ClickHouse the engine powering Tinybird.
In my work, we primarily query against DB2 (a transactional database) and HANA (which can be used for real-time analytics, but we mostly query it in nightly batches for demanding analytical workloads). We then use Qlik Sense, a business intelligence platform, for analyzing the final data. Interestingly, Qlik Sense and ClickHouse share some internal similarities in how they handle analytical queries efficiently. To understand ClickHouse better, let’s review some core database concepts, drawing from the excellent CMU Intro to Database Systems course.
./OLTP vs. OLAP.
- On-Line Transaction Processing(OLTP): Optimized for fast, short transactions that read or update small amounts of data. Think of systems like DB2, designed for many concurrent users performing quick operations.
- On-Line Analytical Processing(OLAP): Designed for complex queries that read large amounts of data to compute aggregates. This is where ClickHouse shines.
- Hybrid Transaction + Analytical Processing: Systems like HANA attempt to combine OLTP and OLAP capabilities within the same database instance.
OLAP excels at queries that span multiple entities and require aggregation:
SELECT
COUNT(U.lastLogin),
EXTRACT(month FROM U.lastLogin) AS month
FROM
useracct AS U
WHERE U.hostname LIKE '%.gov'
GROUP BY
EXTRACT(month FROM U.lastLogin)
./Decomposition Storage Model (DSM) / Columnar Storage
ClickHouse, like Qlik Sense’s engine, employs a columnar storage approach (also known as Decomposition Storage Model). Instead of storing data row by row, a columnar database stores all values for a single attribute contiguously in a block of data. This is incredibly efficient for OLAP workloads that typically scan a subset of a table’s attributes.

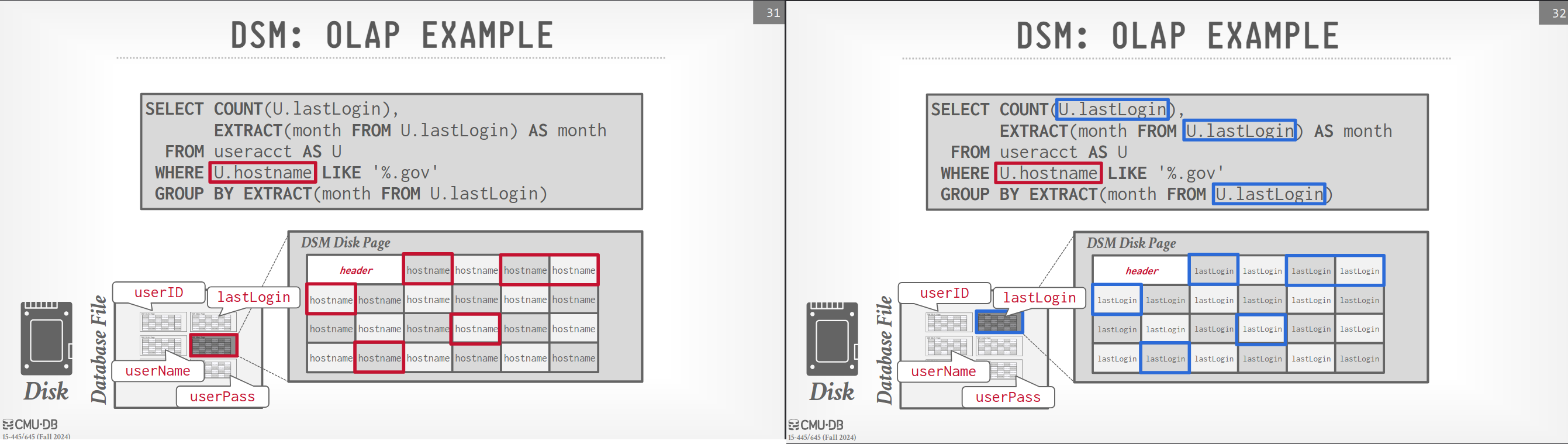
Columnar storage minimizes wasted I/O by only reading the necessary data. It also leads to faster query processing due to increased data locality and better cache utilization.
While excellent for analytical queries, columnar storage can be less efficient for point queries, inserts, updates, and deletes due to the overhead of tuple splitting, stitching, and reorganization.
./Columnar Compression
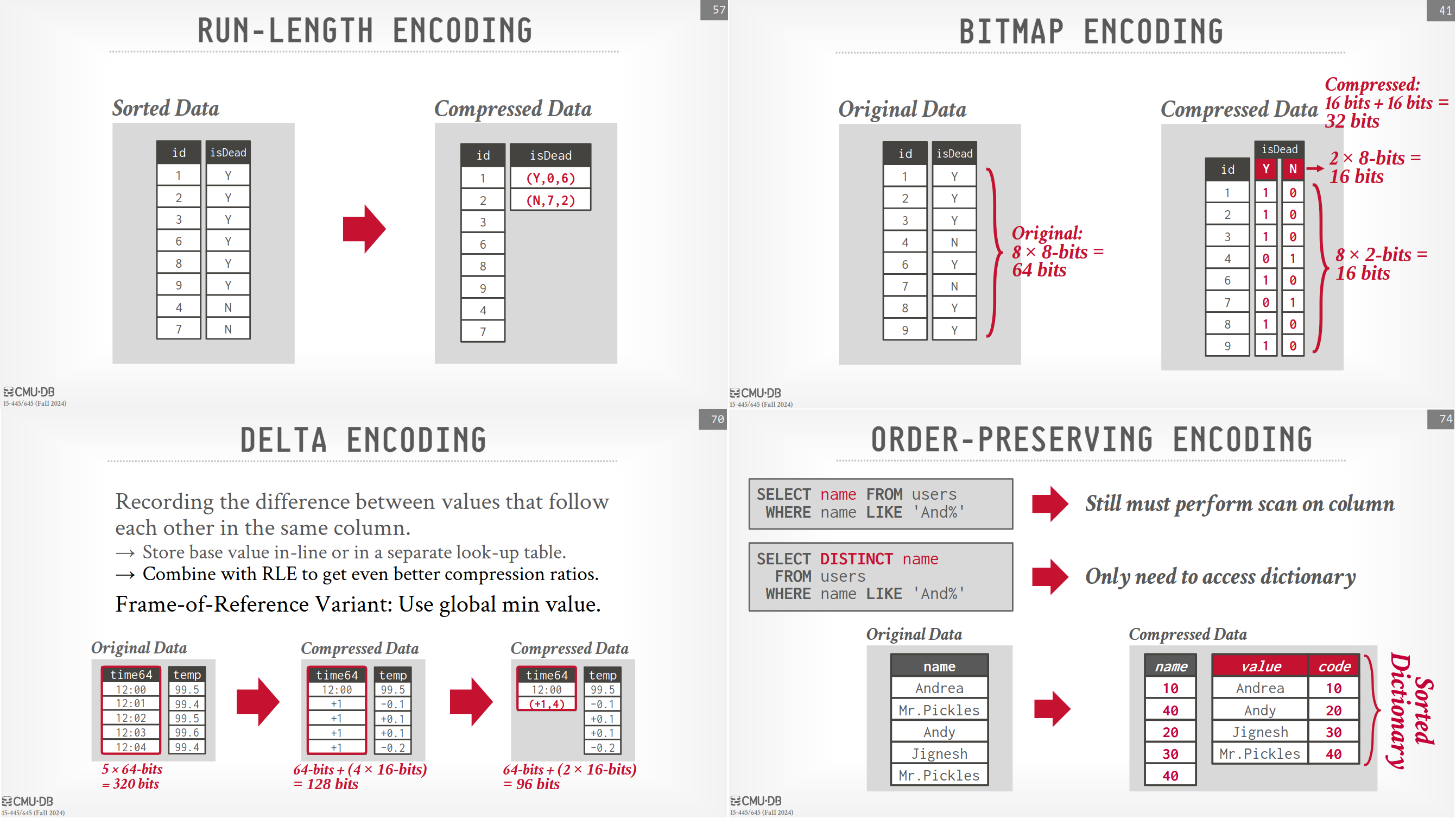
ClickHouse further optimizes its columnar storage with various compression techniques, ideally allowing the DBMS to operate directly on compressed data:
- Run-Length Encoding (RLE): Compresses sequences of identical values.
- Bitmap Encoding: Uses bitmaps for low-cardinality attributes. Compressed bitmaps, such as Roaring Bitmaps, are particularly effective for sparse data.
- Delta Encoding: Stores the difference between consecutive values, rather than the full values themselves.
- Dictionary Compression: Replaces frequently occurring values with smaller representations, using a dictionary for lookup.
./Conclusion
These are just a few of the key reasons behind ClickHouse’s performance. We’ll explore distributed database systems and other contributing factors in a future post.
./Building My Own ClickHouse
To deepen my understanding, I’ve started exploring the “build-my-own” approach using the MCP tool. This project aims to recreate ClickHouse from scratch, guided by AI, offering a practical and insightful learning experience.