Real-Time Analytics Fundamentals
In this final post of the series, I’ll review key concepts from the Principios de analítica en tiempo real course, covering topics I missed in my previous posts.
This is a quick review about he topics cover on the course.
./Hardware Considerations

- Volatile storage is significantly faster than non-volatile storage.
- Random access on non-volatile storage is much slower than sequential access. Optimize for sequential reads whenever possible.
- In cloud environments, cached data can be evicted unexpectedly due to shared resources.
./Source Data and Ingestion
Efficient data ingestion is crucial for real-time analytics:
- Minimize disk I/O by ingesting data in larger batches rather than individual rows.
- When working with files, prefer multiple smaller files over one massive file for improved parallelism.
- Use streaming-friendly compression algorithms like
gz. - Structured data (e.g., Parquet, ORC) enables faster processing compared to unstructured or semi-structured data.
- Data is often categorized into event tables (large, high-volume) and dimension tables (smaller, descriptive).
Ingestion Patterns
- Upsert: Insert new data and update existing records if a match is found.
- Full Replace: Completely replace existing data, typically used for dimension tables.
- Partial Replace: Replace a subset of data (e.g., data for a specific month).
./Storing Data
Optimizing data storage is essential for query performance:
- A well-defined schema ensures data homogeneity and enables efficient query planning.
- Compression reduces data transfer time but increases CPU load for decompression. Choose an appropriate algorithm based on your workload (e.g., LZ4 for speed, ZSTD for compression ratio).
- Use the smallest appropriate data types to minimize memory usage.
- Sorted data can speed up queries, but the optimal sort order depends on the specific queries.
- Indexes provide fast data access, similar to an index in a book.
./Query Optimization
Efficient querying relies on several strategies:
- Parallelization: Distribute queries across multiple machines or CPU cores.
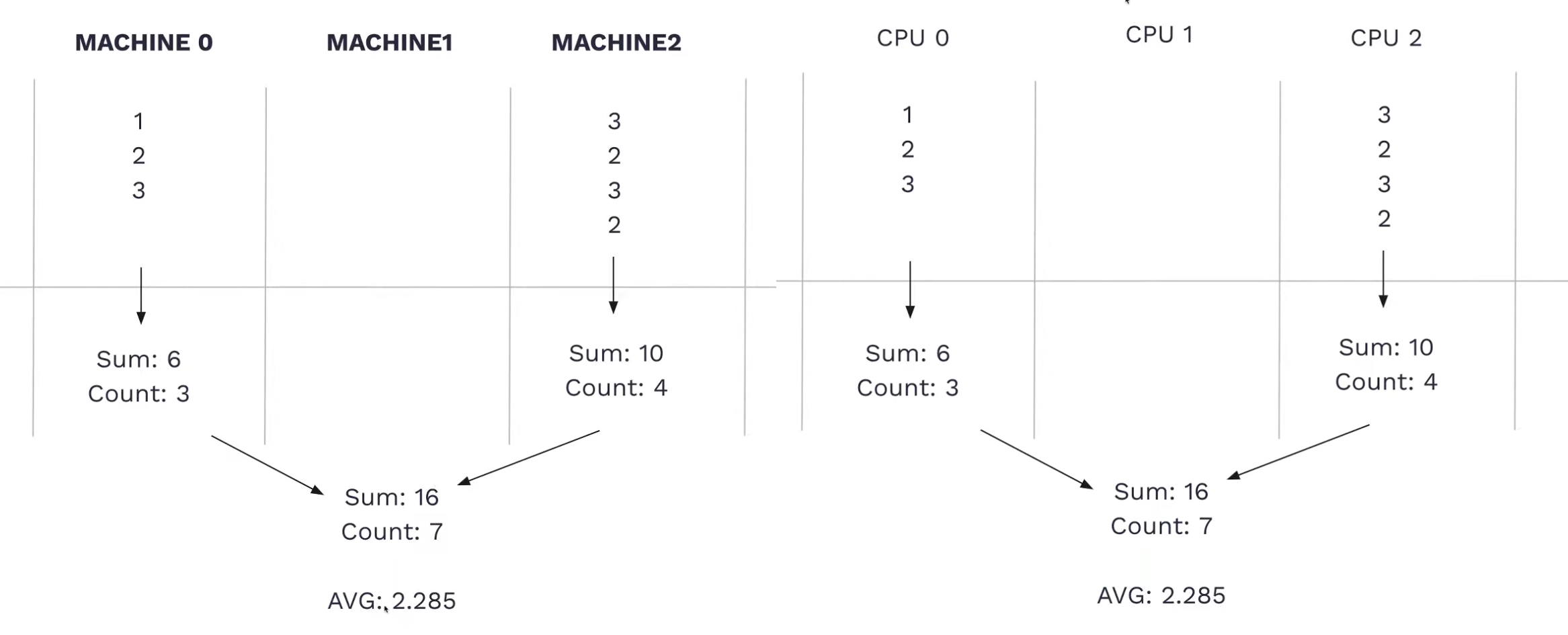
- Minimize Data Read: The fastest query is the one that reads no data. Use indexes, filters, and prefilters effectively.
- Order of Operations: Perform lightweight, indexed operations first to reduce the data volume before applying more complex operations.
- Data Type Awareness: Consider the performance implications of different data types (e.g., integer vs. string comparisons).
- Join Strategies: While denormalization can avoid joins during ingestion, joins are often unavoidable. Choose appropriate join algorithms (e.g., merge join) and optimize join conditions.
- Algorithm Selection: Use specialized algorithms optimized for specific tasks (e.g.,
uniqfor approximate unique counts,uniqExactfor precise counts).
./Materialized Views
Materialized views pre-compute and store query results, trading storage space for faster query performance:
- Maintenance: Materialized views require synchronization with the underlying data.
- Cost Savings: While increasing storage costs, materialized views can significantly reduce compute costs, resulting in overall savings.
- Intermediate States: Materialized views can store intermediate results, especially useful in parallelized queries. New data ingested adds new intermediate states. When querying, specify to merge these intermediate states.
./Exposing the Data
Tinybird typically exposes data through APIs. Implement robust data testing and benchmarking:
- Data Quality Checks: Verify data integrity by checking row counts, key aggregations, and missing values. Automate these tests as part of your data pipeline..
- Benchmarking: Create realistic benchmarks that mimic expected user load.
./Scaling
Scaling distributed systems introduces significant complexity:
- Sharding and Replication: Sharding distributes data across multiple machines for parallel processing, while replication provides redundancy and high availability, also speed.
- Resource Allocation: Dedicate separate resources for ingestion, processing, and querying to maximize performance and avoid resource contention. For example, separate the ingestion workload (ordering, compression) from the query-serving databases.